



Introduction
Kubernetes enables the deployment of a complex system, called the main application here, by integrating several microservices in many innovative fashions. The main application can be an online retail shopping website or a web service that supports airline ticket reservations. For example, one can build a full-fledged online shopping website by combining several microservices such as NGINX as front-end servers, Tomcat as web services, Postgres Database for storage. One can further integrate Logstash and Elasticsearch to enhance the user experience with advanced analytics. Each of the microservices can be updated and scaled independently to meet the changing demands on features and scales.
One or more metrics, called main application Key Performance Indicators (KPIs), are monitored carefully to gauge the performance of the main application and to ensure the proper operation of the system. Among those KPIs, some could be used as an indicator of the workload of the main application, and others are used to measure the performance of the main application. These KPIs can be influenced by the number of microservice PODs and resources like CPU and memory allocated to each of the microservices. Finding the right amount of resources and the right number of pods of these microservices to achieve the target performance goal of the main application is a complicated task. It is most likely done by a trial-and-error approach with a lot of manual processes.
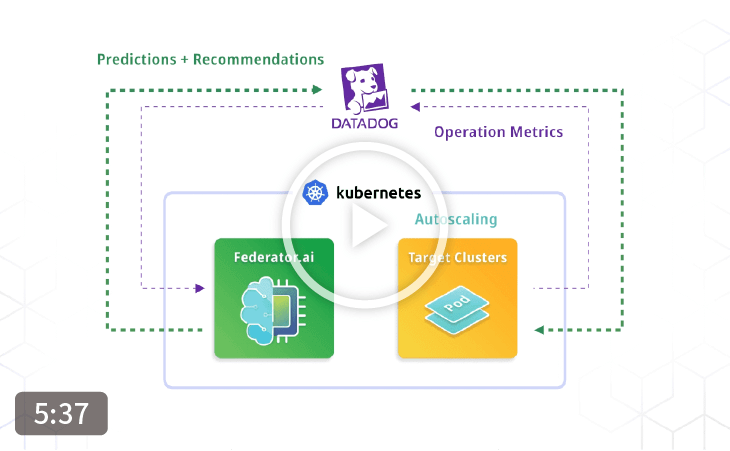
Federator.ai, an AIOps platform for Kubernetes/OpenShift clusters from ProphetStor, tackles the challenge of how to adjust microservices to improve the main application KPIs with Machine Learning-based Multi-Layer correlation, prediction, and application-aware horizontal POD autoscaling (HPA). Traditionally, it is possible to perform workload prediction for each of the microservices in the main application and provides recommendations and/or autoscaling of individual microservices. However, the resources required for performing prediction for every microservice could become cost-prohibitive. Furthermore, it does not provide a clear view of how the workload of the main application impacts the workload of each individual microservice.
With Federator.ai’s patent-pending technology, the correlation among the main application KPIs and the metrics of the constituted microservices are analyzed automatically and dynamically to determine the relevance of microservices against the main application KPIs. Specifically, one can now observe the propagation of workload from the main application to each individual microservice through the Multi-Layer correlation algorithm. In conjunction with the main application workload prediction, Federator.ai can effectively predict the workload of the constituted microservices of the main application. This allows the system to use only a fraction of resources to achieve the predictions of multiple microservices within the main application.
The results from the Multi-Layer correlation analysis further shed light on the relationship among performance metrics of multiple microservices. For example, it is easy to see that, with an increase in the main application workload, which microservice’s performance metrics would be impacted and how much the impact is. Utilizing application-aware HPA, Federator.ai can adjust the PODs needed to support the correlated microservices to reach the targeted KPIs of the main application.
One or more metrics, called main application Key Performance Indicators (KPIs), are monitored carefully to gauge the performance of the main application and to ensure the proper operation of the system. Among those KPIs, some could be used as an indicator of the workload of the main application, and others are used to measure the performance of the main application. These KPIs can be influenced by the number of microservice PODs and resources like CPU and memory allocated to each of the microservices. Finding the right amount of resources and the right number of pods of these microservices to achieve the target performance goal of the main application is a complicated task. It is most likely done by a trial-and-error approach with a lot of manual processes.
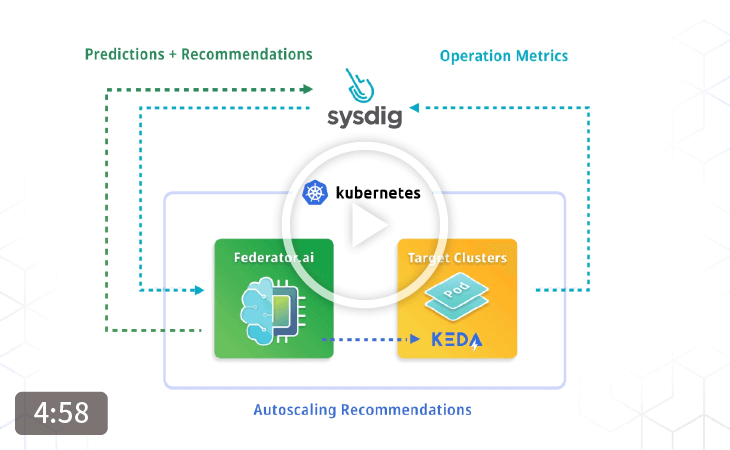
Federator.ai, an AIOps platform for Kubernetes/OpenShift clusters from ProphetStor, tackles the challenge of how to adjust microservices to improve the main application KPIs with Machine Learning-based Multi-Layer correlation, prediction, and application-aware horizontal POD autoscaling (HPA). Traditionally, it is possible to perform workload prediction for each of the microservices in the main application and provides recommendations and/or autoscaling of individual microservices. However, the resources required for performing prediction for every microservice could become cost-prohibitive. Furthermore, it does not provide a clear view of how the workload of the main application impacts the workload of each individual microservice.
With Federator.ai’s patent-pending technology, the correlation among the main application KPIs and the metrics of the constituted microservices are analyzed automatically and dynamically to determine the relevance of microservices against the main application KPIs. Specifically, one can now observe the propagation of workload from the main application to each individual microservice through the Multi-Layer correlation algorithm. In conjunction with the main application workload prediction, Federator.ai can effectively predict the workload of the constituted microservices of the main application. This allows the system to use only a fraction of resources to achieve the predictions of multiple microservices within the main application.
The results from the Multi-Layer correlation analysis further shed light on the relationship among performance metrics of multiple microservices. For example, it is easy to see that, with an increase in the main application workload, which microservice’s performance metrics would be impacted and how much the impact is. Utilizing application-aware HPA, Federator.ai can adjust the PODs needed to support the correlated microservices to reach the targeted KPIs of the main application.
An Example System
Let’s take a look at a system with a collection of NGINX front-end servers that generate access logs. The access logs are picked up by a Kafka client as a producer and are injected into a Kafka cluster. This is followed by Kafka consumers retrieving the log entries from the Kafka cluster and injecting them into an Elasticsearch cluster. For this system, we would like to obtain and analyze the real-time usages of the system through dashboards or analytics tools tied to an Elasticsearch cluster. In particular, Filebeats is used to read NGINX logs and then write them into Kafka brokers. This example is derived from this article on Medium.
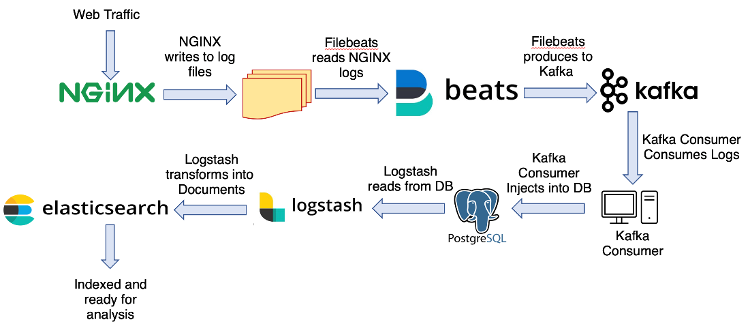
In order to satisfy the real-time usage via the Elasticsearch cluster, one of the main application KPIs could be the delay between the time when an NGINX log entry is created and the time when the corresponding content is indexed in the Elasticsearch. The various microservices of the system will need to be adapted to keep the KPI, the delay, within a target range. In order to compute the average delay of the main application KPI, one can sum the average delay time at major components, such as:
- the average Elasticsearch indexing time per document: the total time spent indexing documents to an index divided by the total number of documents indexed to an index
- the Kafka Consumer queuing delay per message: the consumer lags divided by the current log offset change rate).
- Finding the Correlation
- Application-aware HPA
- Predicting with Multi-Layer Correlation
Finding the Correlation
A microservice can be characterized by its own metrics (also known as microservice KPIs) and can be monitored to ensure the microservice is running properly. The main application KPI can be viewed as a function of the metrics of the microservices constituting the main application. After system administrators specify what microservice metrics are possibly related to the main application KPIs, Federator.ai dynamically determines whether the correlation exists between the main application KPIs and the microservice metrics.
For example, an increase in the main application KPI (delay of indexing NGINX log entry in the Elasticsearch) is observed. Federator.ai further identifies the following:
For example, an increase in the main application KPI (delay of indexing NGINX log entry in the Elasticsearch) is observed. Federator.ai further identifies the following:
- Kafka consumer queue latency is also increased significantly.
- The average Elasticsearch indexing time is not changing much.
- The number of unprocessed bytes in Filebeats is not changing much.
Application-Aware HPA
Kubernetes’ Horizontal POD Autoscaling (HPA) allows each microservice to be tuned by adjusting the number of PODs supporting the respective microservice, based on metrics like CPU, memory, application-specific metrics, and the combination of many metrics. In particular, one may increase the number of PODs if the respective microservice’s performance metrics do not meet their target range, and conversely, one may decrease the number of PODs if the performance metrics above their target range.
Federator.ai supports application-aware HPA that incorporates multiple metrics to meet the application-specific API. In particular, for Kafka consumers, we support a microservice KPI of target queue latency, which is defined as the consumer lags divided by the consumption rate at the respective time. We utilize Kafka’s log offsets and current offsets to compute the production rates and consumption rates, which are used to determine the capacity of each consumer POD. Then, the number of PODs for the microservice is determined by dividing the production rate and the consumer capacity. Please refer to our companion white paper on this subject: Why Horizontal Pod Autoscaling in Kubernetes Needs to Be Application-Aware.
Federator.ai supports application-aware HPA that incorporates multiple metrics to meet the application-specific API. In particular, for Kafka consumers, we support a microservice KPI of target queue latency, which is defined as the consumer lags divided by the consumption rate at the respective time. We utilize Kafka’s log offsets and current offsets to compute the production rates and consumption rates, which are used to determine the capacity of each consumer POD. Then, the number of PODs for the microservice is determined by dividing the production rate and the consumer capacity. Please refer to our companion white paper on this subject: Why Horizontal Pod Autoscaling in Kubernetes Needs to Be Application-Aware.
Predicting with Multi-Layer Correlation
To implement effective HPA for microservices, we not only want to use the metrics collected from microservices to measure the performance of such microservices, but also need to identify the metrics that are good indicators of microservice workloads and provide predictions of these workload metrics. This is to ensure the recommendations make sense in the future if the workload metrics exhibit patterns that can be uncovered. From the Kafka example, we learn that, for most microservices, traditional metrics such as CPU and memory utilization are not good indicators for microservice workloads. Instead, Kafka production rate is a better workload metric for the Kafka consumers. Workload metrics for microservices are also needed in learning the capacity of microservice PODs, which is essential in deciding the right number of pods in application-aware HPA.
Predicting workload metrics independently for all the microservices in the main application needs substantial resources. However, when utilizing Multi-Layer correlation analysis for prediction calculation done in parallel, the cost of the resources is greatly reduced. The Multi-Layer correlation analysis also explores the correlation among the relevant metrics. In our example, the rate of NGINX writing access logs, the rate of Kafka producer writing into Kafka cluster, the rate of log offset change, the consumption rate, the indexing rate will likely be correlated to each other. Similarly, the CPU, memory usage, network traffic of respective PODs may also correlate to each other too.
In our example, a key metric, such as the rate of NGINX writing access logs, is used as the workload for the main application. It is used as the main metric for the Multi-Layer correlation analysis, and the relationship of this metric and the rest of the above-mentioned metrics are analyzed. The predicted workload of individual microservice is then derived from the prediction of the main application workload using the correlation results. With this information and other relevant metrics, the application-aware HPA can automatically scale the right number of pods of relevant microservices to meet the target main application KPI.
Predicting workload metrics independently for all the microservices in the main application needs substantial resources. However, when utilizing Multi-Layer correlation analysis for prediction calculation done in parallel, the cost of the resources is greatly reduced. The Multi-Layer correlation analysis also explores the correlation among the relevant metrics. In our example, the rate of NGINX writing access logs, the rate of Kafka producer writing into Kafka cluster, the rate of log offset change, the consumption rate, the indexing rate will likely be correlated to each other. Similarly, the CPU, memory usage, network traffic of respective PODs may also correlate to each other too.
In our example, a key metric, such as the rate of NGINX writing access logs, is used as the workload for the main application. It is used as the main metric for the Multi-Layer correlation analysis, and the relationship of this metric and the rest of the above-mentioned metrics are analyzed. The predicted workload of individual microservice is then derived from the prediction of the main application workload using the correlation results. With this information and other relevant metrics, the application-aware HPA can automatically scale the right number of pods of relevant microservices to meet the target main application KPI.
Concluding Remarks
We examine the strategies of extending the application-aware HPA from one application or one microservice to a system consisting of many applications and microservices. Using Federator.ai Multi-Layer correlation and prediction technology, we can analyze the workload propagation throughout the system and the relationship between relevant performance metrics of each microservice. The potential bottleneck within the system when the main workload increases could be, therefore, easily identified.
Federator.ai provides system-level Auto-Scaling by machine-learning-based correlation among multi-layer metrics collected by monitoring services. It also considers the KPI of the main application. A major benefit of Multi-Layer correlation analysis is the reduction of computation resources in workload predictions for microservices in the system. Accurate workload prediction is essential for effective HPA and maintaining overall performance target with the right amount of resources. Applying a machine learning algorithm for the prediction of each individual microservice requires a high amount of computation resources. With Multi-Layer correlation analysis, the cost of workload prediction tasks is greatly reduced, up to 1000s of times. The machine learning approach to optimize operational performance and cost in a Cloud-Native environment can finally become practical.
Federator.ai provides system-level Auto-Scaling by machine-learning-based correlation among multi-layer metrics collected by monitoring services. It also considers the KPI of the main application. A major benefit of Multi-Layer correlation analysis is the reduction of computation resources in workload predictions for microservices in the system. Accurate workload prediction is essential for effective HPA and maintaining overall performance target with the right amount of resources. Applying a machine learning algorithm for the prediction of each individual microservice requires a high amount of computation resources. With Multi-Layer correlation analysis, the cost of workload prediction tasks is greatly reduced, up to 1000s of times. The machine learning approach to optimize operational performance and cost in a Cloud-Native environment can finally become practical.