
Introduction
The workloads running in Kubernetes clusters are characterized by their respective Key Performance Indicators (KPIs). To meet diverse, application-specific KPI objectives, Kubernetes implements a generic framework known as Horizontal Pod Autoscaling (HPA), which scales up and down the number of pods with the same characteristics. The HPA controller can perform autoscaling using either standard metrics like CPU utilization or custom metrics based on the following formula. At first glance, this approach seems reasonable. However, this whitepaper shows that such a method is too simplistic for many applications, potentially leading to resource wastage or decreased performance.
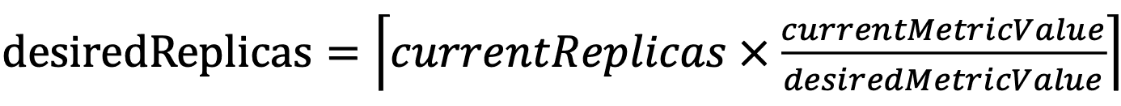
It has been observed that Application KPIs are not necessarily directly related to Pods’ CPU and memory utilization. Scaling the number of Pods based on a single, generic metric may not result in optimal KPI outcomes for the underlying applications. Multiple metrics may be necessary for many applications, such as Kafka consumer workloads to determine the appropriate number of consumers required to process Kafka broker messages without introducing excessive processing latency. In this context, message processing latency could serve as the KPI for the application. More importantly, most workloads exhibit predictable behaviors. Leveraging these behaviors can distinguish an application-aware HPA solution from other naive approaches.
We also demonstrate that by utilizing application-specific metrics and machine learning-based workload prediction, ProphetStor’s application-aware HPA achieves an over 40% reduction in the number of required replicas compared to a standard CPU-utilization-based HPA.
Kubernetes Scaling with Application-Awareness
In Kubernetes, scaling criteria can be based on metrics such as CPU utilization, as defined in autoscaling/v1. The HPA framework has been extended to support Memory and other generic metrics defined in autoscaling/v2beta2, as well as the Watermark Pod Autoscaler (WPA) developed by Datadog.
By integrating Datadog’s agents running on the nodes, one can collect application-specific metrics, such as Kafka consumer lags and log offsets, in a unified and deployment-proof manner. Our solution leverages the ease of collecting application metrics enabled by Datadog’s agents and focuses on transforming the collected data into KPI-aware HPA actions.
KPI for Kafka Consumer Performance
The KPI we focus on is the duration a message remains in Kafka brokers before being committed by a Kafka consumer. Specifically, we define this KPI as queue latency, measured as Kafka’s consumer lag divided by the total consumer message consumption rate. This KPI captures several critical aspects of Kafka as a messaging service. The KPI improves as the number of consumers approaches the number of partitions and worsens as the number of consumers decreases toward 1 or any minimum allowed.
In a real-world setup, Kafka producers inject messages into Kafka brokers at variable rates. To satisfy a target KPI, such as latency between 1 and 5 seconds, there are several possible strategies as the workload fluctuates:
- Over-provisioning: Deploying many consumers to ensure latency remains below 5 seconds.
- Under-provisioning: Using too few consumers leads to uncontrollable latency.
- Dynamic Adjustment: Modifying the number of consumers in real-time so that a smaller, optimal number can meet the target KPI.
Option 1 is the traditional approach before the availability of HPA, but it can be costly if over-provisioned for an extended period. Option 2 is impractical because it disregards the KPI, potentially resulting in ever-increasing consumer lag. Option 3 is supported by HPA algorithms, including ProphetStor’s application-aware solution.
Generic HPA
The Kubernetes autoscaling/v1 framework supports automatic scaling of pods based on observed CPU utilization, commonly known as generic HPA. These generic HPA controllers can be configured to scale the number of pods up or down based on a target average CPU utilization across all pods in the same replica set. For example, if a target average CPU utilization of 70% is set and this threshold is exceeded, the HPA controller will increase the number of replicas to lower the average CPU utilization closer to the target. Conversely, the controller will reduce the number of replicas when the average CPU utilization falls below the target. In addition to autoscaling/v1, the newer autoscaling/v2beta2 version extends its support to additional standard and custom metrics.
The following graphs depict a scenario where a Kafka producer injects messages into brokers, and the consumers consume and commit those messages. The blue line in the top-right widget shows the varying message production rate, which corresponds to the consumers’ workload. In the top-left widget, the blue line shows the number of replicas recommended by the autoscaling/v1 HPA controller with a target CPU utilization of 70%. For comparison, the yellow line in the same widget represents the recommendation from ProphetStor’s application-aware HPA. ProphetStor’s application-aware HPA uses 40% fewer replicas to manage the dynamically changing workload after an initial AI algorithm training period.
TThe top-right widget illustrates the production rate (change in log offset per minute), consumption rate (change in current offset per minute), and the predicted production rate in yellow. The bottom-right widget shows consumer latency over time, which is our KPI.
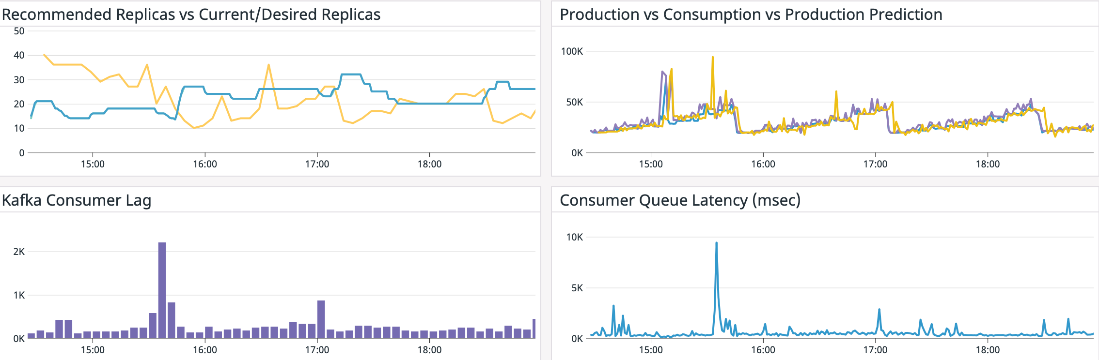
Kafka consumer’s performance, which determines the number of replicas needed to meet a given KPI, depends on various factors: how frequently the brokers are polled, how often commits are made to brokers, and how quickly the consumers can process messages. These operations can be further characterized as CPU-bound, IO-bound, or a mixture of both. In general, it’s challenging to control the application KPI based solely on CPU thresholds or other generic metrics.
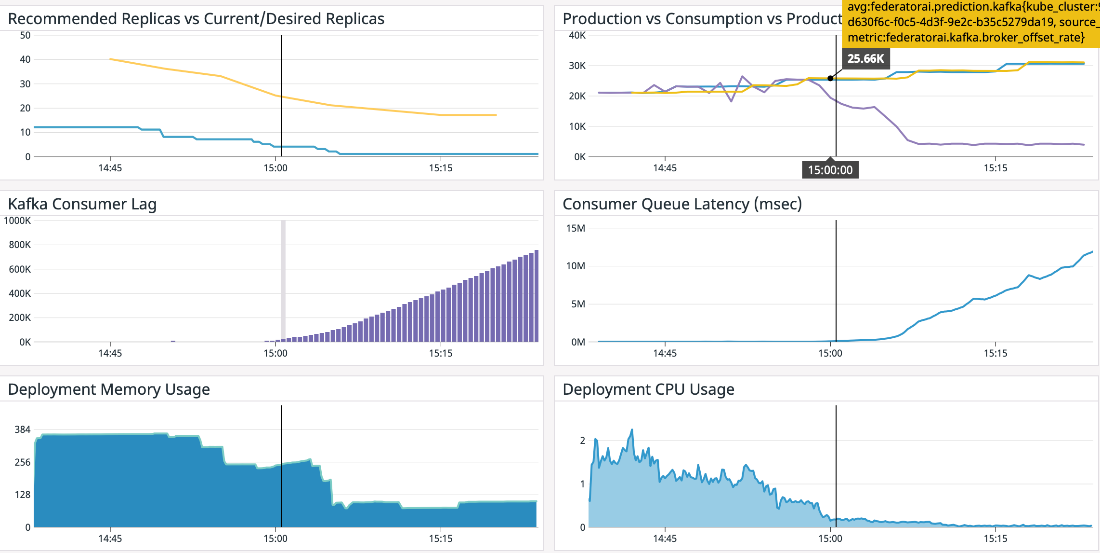
Here is an example of an incorrect setting of HPA autoscaling target CPU utilization to 80%, leading to under-provisioning of consumers and excessive queue latency. This is because the average CPU utilization never exceeds 80%, even with ever-increasing consumer lags in the system. In the top-left widget, the blue line represents the number of consumer replicas, starting at 10 and eventually dropping to 1. This under-provisioning results in excessively high queue latency.
ProphetStor’s Application-Aware HPA
To meet the application-specific KPIs, we introduce a class of algorithms that measure and predict relevant metrics tailored to Kubernetes HPA. Datadog’s agents enable the effective collection of application metrics and seamless deployment of ProphetStor’s autoscaling recommendations without additional instrumentation.
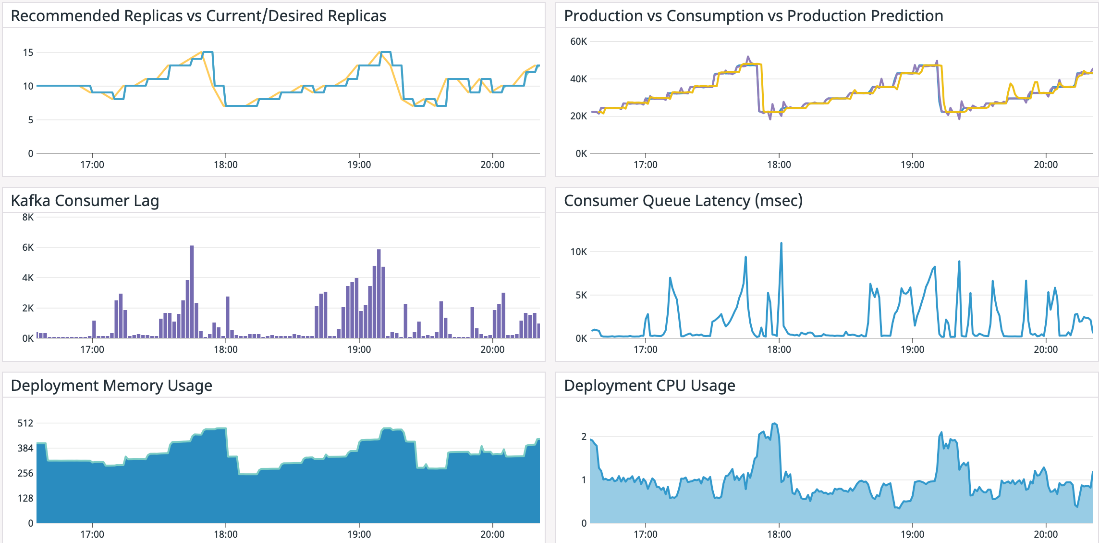
Here are the results of the same workload we presented earlier. The top-left widget shows the current number of consumer replicas in blue and the recommended number of replicas in yellow. The top-right widget displays the production rate, consumption rate, and predicted production rate, all in sync. The KPI of consumer queue latency is shown in the middle-right widget.
The results demonstrate that ProphetStor’s application-aware HPA can efficiently adjust the number of consumer replicas in response to the changing production rate while maintaining an average consumer queue latency of 1.4 seconds, with our target KPI set at 6 seconds. The peak number of replicas is 15, and the minimum is 7. Compared to generic HPA, our solution requires 40% fewer consumer replicas while still achieving a reasonable KPI.
Our Kafka Consumer HPA algorithm is designed to balance the convergence time for estimating consumer capacity with the target KPI of queue latency, all while minimizing the number of consumer replicas needed for varying workloads. The algorithm dynamically calculates consumer capacity over time to determine how many messages per minute each consumer can handle at peak loads without sacrificing the KPI, which is the latency of messages staying in the Kafka brokers. Because capacity estimation is performed dynamically for each consumer group, the algorithm can adapt to various environments without operator intervention. The only constraint for each consumer group is that the maximum number of consumer replicas cannot exceed the number of partitions in a topic.
When determining the appropriate number of consumer replicas to use, we could divide the current production rate by the estimated consumer capacity. However, this approach could lead to significant consumer lag, causing the KPI to fall outside our target range during sudden increases in production rate. To maintain the KPI within our target range, we implemented two complementary strategies: using our proprietary machine-learning-based workload prediction for production rates to determine the number of replicas, and slightly over-provisioning the number of replicas. With workload prediction, we use the maximum predicted production rates in the near future, rather than past observations, to determine the number of replicas. For slight over-provisioning, we apply a policy of 10% over-provisioning. Combined, these strategies allow us to maintain queue latency (our KPI) within the target range while adapting consumer replicas to minimize the potential for over-provisioning.
Conclusion
Application workloads are dynamic, making it challenging to provide Just-in-Time Fitted, right-sized resources or the correct number of replicas to service workloads throughout their lifecycle. Often, systems are over-provisioned with too many replicas or resources because the system’s behavior is not clearly understood.
Autoscaling with HPA offers a solution to automatically adjust the resources needed to support dynamic workloads. However, we have demonstrated that CPU utilization is not always the right indicator for the KPI in many real-world workloads. Additionally, determining the appropriate target CPU utilization to achieve effective HPA while maintaining a good KPI is complex and often unfeasible, especially in dynamic environments. Although Kubernetes Native HPA and Datadog’s WPA support standard and custom metrics, they employ straightforward scaling algorithms that cannot effectively integrate multiple metrics.
By using the right metrics for application workloads and leveraging machine-learning-based workload prediction, we can achieve better HPA, optimizing both resource utilization and application KPIs. Our application-aware HPA intelligently correlates multiple application metrics with KPI targets to determine the proper Kafka consumer capacity. ProphetStor’s Federator.ai provides machine-learning-based workload prediction and operational plans that dynamically adjust the number of replicas based on workloads, all while maintaining the KPI target. We have shown that application awareness is essential for the effective operation of Kubernetes’ autoscaling. Coupled with the understanding of the operating environment and dynamic resource adjustments, we can significantly improve utilization and performance.